Mixed logit with simulated data
Contents
Mixed logit with simulated data¶
This is a demo of stochastic variational inference (SVI) using simulated data for 500 individuals
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import sys
sys.path.insert(0, "/home/rodr/code/amortized-mxl-dev/release")
import logging
import time
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Fix random seed for reproducibility
np.random.seed(42)
Generate simulated data¶
We predefine the fixed effects parameters (true_alpha) and random effects parameters (true_beta), as well as the covariance matrix (true_Omega), and sample simulated choice data for 500 respondents (num_resp), each with 5 choice situations (num_menus). The number of choice alternatives is set to 5.
from core.dcm_fakedata import generate_fake_data_wide
num_resp = 500
num_menus = 5
num_alternatives = 5
true_alpha = np.array([-0.8, 0.8, 1.2])
true_beta = np.array([-0.8, 0.8, 1.0, -0.8, 1.5])
# dynamic version of generating Omega
corr = 0.8
scale_factor = 1.0
true_Omega = corr*np.ones((len(true_beta),len(true_beta))) # off-diagonal values of cov matrix
true_Omega[np.arange(len(true_beta)), np.arange(len(true_beta))] = 1.0 # diagonal values of cov matrix
true_Omega *= scale_factor
df = generate_fake_data_wide(num_resp, num_menus, num_alternatives, true_alpha, true_beta, true_Omega)
df.head()
Generating fake data...
Error: 45.16
| ALT1_XF1 | ALT1_XF2 | ALT1_XF3 | ALT1_XR1 | ALT1_XR2 | ALT1_XR3 | ALT1_XR4 | ALT1_XR5 | ALT2_XF1 | ALT2_XF2 | ... | ALT5_XR1 | ALT5_XR2 | ALT5_XR3 | ALT5_XR4 | ALT5_XR5 | choice | indID | menuID | obsID | ones | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.374540 | 0.950714 | 0.731994 | 0.502929 | 0.474680 | 0.301972 | 0.539872 | 0.248391 | 0.598658 | 0.156019 | ... | 0.237133 | 0.323644 | 0.292095 | 0.797652 | 0.171230 | 2 | 0 | 0 | 0 | 1 |
| 1 | 0.183405 | 0.304242 | 0.524756 | 0.608472 | 0.051355 | 0.549528 | 0.063914 | 0.175877 | 0.431945 | 0.291229 | ... | 0.981368 | 0.299731 | 0.278902 | 0.973245 | 0.728234 | 2 | 0 | 1 | 1 | 1 |
| 2 | 0.607545 | 0.170524 | 0.065052 | 0.585298 | 0.699323 | 0.709927 | 0.763336 | 0.067189 | 0.948886 | 0.965632 | ... | 0.839992 | 0.718722 | 0.500256 | 0.273207 | 0.877216 | 3 | 0 | 2 | 2 | 1 |
| 3 | 0.662522 | 0.311711 | 0.520068 | 0.776655 | 0.837907 | 0.140789 | 0.314813 | 0.424885 | 0.546710 | 0.184854 | ... | 0.296403 | 0.507946 | 0.230841 | 0.514504 | 0.683332 | 3 | 0 | 3 | 3 | 1 |
| 4 | 0.388677 | 0.271349 | 0.828738 | 0.085521 | 0.870117 | 0.593746 | 0.989603 | 0.025592 | 0.356753 | 0.280935 | ... | 0.584885 | 0.684462 | 0.256079 | 0.832849 | 0.449690 | 0 | 0 | 4 | 4 | 1 |
5 rows × 45 columns
Mixed Logit specification¶
We now make use of the developed formula interface to specify the utilities of the mixed logit model.
We begin by defining the fixed effects parameters, the random effects parameters, and the observed variables. This creates instances of Python objects that can be put together to define the utility functions for the different alternatives.
Once the utilities are defined, we collect them in a Python dictionary mapping alternative names to their corresponding expressions.
from core.dcm_interface import FixedEffect, RandomEffect, ObservedVariable
# define fixed effects parameters
B_XF1 = FixedEffect('BETA_XF1')
B_XF2 = FixedEffect('BETA_XF2')
B_XF3 = FixedEffect('BETA_XF3')
# define random effects parameters
B_XR1 = RandomEffect('BETA_XR1')
B_XR2 = RandomEffect('BETA_XR2')
B_XR3 = RandomEffect('BETA_XR3')
B_XR4 = RandomEffect('BETA_XR4')
B_XR5 = RandomEffect('BETA_XR5')
# define observed variables
for attr in df.columns:
exec("%s = ObservedVariable('%s')" % (attr,attr))
# define utility functions
V1 = B_XF1*ALT1_XF1 + B_XF2*ALT1_XF2 + B_XF3*ALT1_XF3 + B_XR1*ALT1_XR1 + B_XR2*ALT1_XR2 + B_XR3*ALT1_XR3 + B_XR4*ALT1_XR4 + B_XR5*ALT1_XR5
V2 = B_XF1*ALT2_XF1 + B_XF2*ALT2_XF2 + B_XF3*ALT2_XF3 + B_XR1*ALT2_XR1 + B_XR2*ALT2_XR2 + B_XR3*ALT2_XR3 + B_XR4*ALT2_XR4 + B_XR5*ALT2_XR5
V3 = B_XF1*ALT3_XF1 + B_XF2*ALT3_XF2 + B_XF3*ALT3_XF3 + B_XR1*ALT3_XR1 + B_XR2*ALT3_XR2 + B_XR3*ALT3_XR3 + B_XR4*ALT3_XR4 + B_XR5*ALT3_XR5
V4 = B_XF1*ALT4_XF1 + B_XF2*ALT4_XF2 + B_XF3*ALT4_XF3 + B_XR1*ALT4_XR1 + B_XR2*ALT4_XR2 + B_XR3*ALT4_XR3 + B_XR4*ALT4_XR4 + B_XR5*ALT4_XR5
V5 = B_XF1*ALT5_XF1 + B_XF2*ALT5_XF2 + B_XF3*ALT5_XF3 + B_XR1*ALT5_XR1 + B_XR2*ALT5_XR2 + B_XR3*ALT5_XR3 + B_XR4*ALT5_XR4 + B_XR5*ALT5_XR5
# associate utility functions with the names of the alternatives
utilities = {"ALT1": V1, "ALT2": V2, "ALT3": V3, "ALT4": V4, "ALT5": V5}
We are now ready to create a Specification object containing the utilities that we have just defined. Note that we must also specify the type of choice model to be used - a mixed logit model (MXL) in this case.
Note that we can inspect the specification by printing the dcm_spec object.
from core.dcm_interface import Specification
# create MXL specification object based on the utilities previously defined
dcm_spec = Specification('MXL', utilities)
print(dcm_spec)
----------------- MXL specification:
Alternatives: ['ALT1', 'ALT2', 'ALT3', 'ALT4', 'ALT5']
Utility functions:
V_ALT1 = BETA_XF1*ALT1_XF1 + BETA_XF2*ALT1_XF2 + BETA_XF3*ALT1_XF3 + BETA_XR1_n*ALT1_XR1 + BETA_XR2_n*ALT1_XR2 + BETA_XR3_n*ALT1_XR3 + BETA_XR4_n*ALT1_XR4 + BETA_XR5_n*ALT1_XR5
V_ALT2 = BETA_XF1*ALT2_XF1 + BETA_XF2*ALT2_XF2 + BETA_XF3*ALT2_XF3 + BETA_XR1_n*ALT2_XR1 + BETA_XR2_n*ALT2_XR2 + BETA_XR3_n*ALT2_XR3 + BETA_XR4_n*ALT2_XR4 + BETA_XR5_n*ALT2_XR5
V_ALT3 = BETA_XF1*ALT3_XF1 + BETA_XF2*ALT3_XF2 + BETA_XF3*ALT3_XF3 + BETA_XR1_n*ALT3_XR1 + BETA_XR2_n*ALT3_XR2 + BETA_XR3_n*ALT3_XR3 + BETA_XR4_n*ALT3_XR4 + BETA_XR5_n*ALT3_XR5
V_ALT4 = BETA_XF1*ALT4_XF1 + BETA_XF2*ALT4_XF2 + BETA_XF3*ALT4_XF3 + BETA_XR1_n*ALT4_XR1 + BETA_XR2_n*ALT4_XR2 + BETA_XR3_n*ALT4_XR3 + BETA_XR4_n*ALT4_XR4 + BETA_XR5_n*ALT4_XR5
V_ALT5 = BETA_XF1*ALT5_XF1 + BETA_XF2*ALT5_XF2 + BETA_XF3*ALT5_XF3 + BETA_XR1_n*ALT5_XR1 + BETA_XR2_n*ALT5_XR2 + BETA_XR3_n*ALT5_XR3 + BETA_XR4_n*ALT5_XR4 + BETA_XR5_n*ALT5_XR5
Num. parameters to be estimated: 8
Fixed effects params: ['BETA_XF1', 'BETA_XF2', 'BETA_XF3']
Random effects params: ['BETA_XR1', 'BETA_XR2', 'BETA_XR3', 'BETA_XR4', 'BETA_XR5']
Once the Specification is defined, we need to define the DCM Dataset object that goes along with it. For this, we instantiate the Dataset class with the Pandas dataframe containing the data in the so-called “wide format”, the name of column in the dataframe containing the observed choices and the dcm_spec that we have previously created.
Note that since this is panel data, we must also specify the name of the column in the dataframe that contains the ID of the respondent (this should be a integer ranging from 0 the num_resp-1).
from core.dcm_interface import Dataset
# create DCM dataset object
dcm_dataset = Dataset(df, 'choice', dcm_spec, resp_id_col='indID')
Preparing dataset...
Model type: MXL
Num. observations: 2500
Num. alternatives: 5
Num. respondents: 500
Num. menus: 5
Observations IDs: [ 0 1 2 ... 2497 2498 2499]
Alternative IDs: None
Respondent IDs: [ 0 0 0 ... 499 499 499]
Availability columns: None
Attribute names: ['ALT1_XF1', 'ALT1_XF2', 'ALT1_XF3', 'ALT1_XR1', 'ALT1_XR2', 'ALT1_XR3', 'ALT1_XR4', 'ALT1_XR5', 'ALT2_XF1', 'ALT2_XF2', 'ALT2_XF3', 'ALT2_XR1', 'ALT2_XR2', 'ALT2_XR3', 'ALT2_XR4', 'ALT2_XR5', 'ALT3_XF1', 'ALT3_XF2', 'ALT3_XF3', 'ALT3_XR1', 'ALT3_XR2', 'ALT3_XR3', 'ALT3_XR4', 'ALT3_XR5', 'ALT4_XF1', 'ALT4_XF2', 'ALT4_XF3', 'ALT4_XR1', 'ALT4_XR2', 'ALT4_XR3', 'ALT4_XR4', 'ALT4_XR5', 'ALT5_XF1', 'ALT5_XF2', 'ALT5_XF3', 'ALT5_XR1', 'ALT5_XR2', 'ALT5_XR3', 'ALT5_XR4', 'ALT5_XR5']
Fixed effects attribute names: ['ALT1_XF1', 'ALT1_XF2', 'ALT1_XF3', 'ALT2_XF1', 'ALT2_XF2', 'ALT2_XF3', 'ALT3_XF1', 'ALT3_XF2', 'ALT3_XF3', 'ALT4_XF1', 'ALT4_XF2', 'ALT4_XF3', 'ALT5_XF1', 'ALT5_XF2', 'ALT5_XF3']
Fixed effects parameter names: ['BETA_XF1', 'BETA_XF2', 'BETA_XF3', 'BETA_XF1', 'BETA_XF2', 'BETA_XF3', 'BETA_XF1', 'BETA_XF2', 'BETA_XF3', 'BETA_XF1', 'BETA_XF2', 'BETA_XF3', 'BETA_XF1', 'BETA_XF2', 'BETA_XF3']
Random effects attribute names: ['ALT1_XR1', 'ALT1_XR2', 'ALT1_XR3', 'ALT1_XR4', 'ALT1_XR5', 'ALT2_XR1', 'ALT2_XR2', 'ALT2_XR3', 'ALT2_XR4', 'ALT2_XR5', 'ALT3_XR1', 'ALT3_XR2', 'ALT3_XR3', 'ALT3_XR4', 'ALT3_XR5', 'ALT4_XR1', 'ALT4_XR2', 'ALT4_XR3', 'ALT4_XR4', 'ALT4_XR5', 'ALT5_XR1', 'ALT5_XR2', 'ALT5_XR3', 'ALT5_XR4', 'ALT5_XR5']
Random effects parameter names: ['BETA_XR1', 'BETA_XR2', 'BETA_XR3', 'BETA_XR4', 'BETA_XR5', 'BETA_XR1', 'BETA_XR2', 'BETA_XR3', 'BETA_XR4', 'BETA_XR5', 'BETA_XR1', 'BETA_XR2', 'BETA_XR3', 'BETA_XR4', 'BETA_XR5', 'BETA_XR1', 'BETA_XR2', 'BETA_XR3', 'BETA_XR4', 'BETA_XR5', 'BETA_XR1', 'BETA_XR2', 'BETA_XR3', 'BETA_XR4', 'BETA_XR5']
Alternative attributes ndarray.shape: (500, 5, 40)
Choices ndarray.shape: (500, 5)
Alternatives availability ndarray.shape: (500, 5, 5)
Data mask ndarray.shape: (500, 5)
Context data ndarray.shape: (500, 0)
Neural nets data ndarray.shape: (500, 0)
Done!
As with the specification, we can inspect the DCM dataset by printing the dcm_dataset object:
print(dcm_dataset)
----------------- DCM dataset:
Model type: MXL
Num. observations: 2500
Num. alternatives: 5
Num. respondents: 500
Num. menus: 5
Num. fixed effects: 15
Num. random effects: 25
Attribute names: ['ALT1_XF1', 'ALT1_XF2', 'ALT1_XF3', 'ALT1_XR1', 'ALT1_XR2', 'ALT1_XR3', 'ALT1_XR4', 'ALT1_XR5', 'ALT2_XF1', 'ALT2_XF2', 'ALT2_XF3', 'ALT2_XR1', 'ALT2_XR2', 'ALT2_XR3', 'ALT2_XR4', 'ALT2_XR5', 'ALT3_XF1', 'ALT3_XF2', 'ALT3_XF3', 'ALT3_XR1', 'ALT3_XR2', 'ALT3_XR3', 'ALT3_XR4', 'ALT3_XR5', 'ALT4_XF1', 'ALT4_XF2', 'ALT4_XF3', 'ALT4_XR1', 'ALT4_XR2', 'ALT4_XR3', 'ALT4_XR4', 'ALT4_XR5', 'ALT5_XF1', 'ALT5_XF2', 'ALT5_XF3', 'ALT5_XR1', 'ALT5_XR2', 'ALT5_XR3', 'ALT5_XR4', 'ALT5_XR5']
Bayesian Mixed Logit Model in PyTorch¶
It is now time to perform approximate Bayesian inference on the mixed logit model that we have specified. The generative process of the MXL model that we will be using is the following:
Draw fixed taste parameters \(\boldsymbol\alpha \sim \mathcal{N}(\boldsymbol\lambda_0, \boldsymbol\Xi_0)\)
Draw mean vector \(\boldsymbol\zeta \sim \mathcal{N}(\boldsymbol\mu_0, \boldsymbol\Sigma_0)\)
Draw scales vector \(\boldsymbol\theta \sim \mbox{half-Cauchy}(\boldsymbol\sigma_0)\)
Draw correlation matrix \(\boldsymbol\Psi \sim \mbox{LKJ}(\nu)\)
For each decision-maker \(n \in \{1,\dots,N\}\)
Draw random taste parameters \(\boldsymbol\beta_n \sim \mathcal{N}(\boldsymbol\zeta,\boldsymbol\Omega)\)
For each choice occasion \(t \in \{1,\dots,T_n\}\)
Draw observed choice \(y_{nt} \sim \mbox{MNL}(\boldsymbol\alpha, \boldsymbol\beta_n, \textbf{X}_{nt})\)
where \(\boldsymbol\Omega = \mbox{diag}(\boldsymbol\theta) \times \boldsymbol\Psi \times \mbox{diag}(\boldsymbol\theta)\).
We can instantiate this model from the TorchMXL using the following code. We can the run variational inference to approximate the posterior distribution of the latent variables in the model. Note that since in this case we know the true parameters that were used to generate the simualated choice data, we can pass them to the “infer” method in order to obtain additional information during the ELBO maximization (useful for tracking the progress of VI and for other debugging purposes).
%%time
from core.torch_mxl import TorchMXL
# instantiate MXL model
mxl = TorchMXL(dcm_dataset, batch_size=num_resp, use_inference_net=False, use_cuda=True)
# run Bayesian inference (variational inference)
results = mxl.infer(num_epochs=5000, true_alpha=true_alpha, true_beta=true_beta)
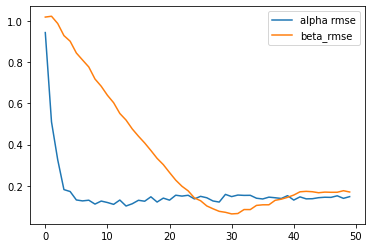
[Epoch 0] ELBO: 11016; Loglik: -4940; Acc.: 0.192; Alpha RMSE: 0.942; Beta RMSE: 1.017
[Epoch 100] ELBO: 5423; Loglik: -4569; Acc.: 0.202; Alpha RMSE: 0.510; Beta RMSE: 1.022
[Epoch 200] ELBO: 4802; Loglik: -3938; Acc.: 0.302; Alpha RMSE: 0.327; Beta RMSE: 0.986
[Epoch 300] ELBO: 4964; Loglik: -3867; Acc.: 0.344; Alpha RMSE: 0.182; Beta RMSE: 0.928
[Epoch 400] ELBO: 4788; Loglik: -3700; Acc.: 0.370; Alpha RMSE: 0.173; Beta RMSE: 0.901
[Epoch 500] ELBO: 4262; Loglik: -3546; Acc.: 0.411; Alpha RMSE: 0.132; Beta RMSE: 0.844
[Epoch 600] ELBO: 4677; Loglik: -3491; Acc.: 0.413; Alpha RMSE: 0.128; Beta RMSE: 0.810
[Epoch 700] ELBO: 4437; Loglik: -3386; Acc.: 0.425; Alpha RMSE: 0.131; Beta RMSE: 0.776
[Epoch 800] ELBO: 4332; Loglik: -3381; Acc.: 0.433; Alpha RMSE: 0.112; Beta RMSE: 0.718
[Epoch 900] ELBO: 4277; Loglik: -3361; Acc.: 0.428; Alpha RMSE: 0.127; Beta RMSE: 0.683
[Epoch 1000] ELBO: 4092; Loglik: -3298; Acc.: 0.450; Alpha RMSE: 0.120; Beta RMSE: 0.639
[Epoch 1100] ELBO: 4055; Loglik: -3236; Acc.: 0.456; Alpha RMSE: 0.111; Beta RMSE: 0.603
[Epoch 1200] ELBO: 4223; Loglik: -3255; Acc.: 0.451; Alpha RMSE: 0.132; Beta RMSE: 0.551
[Epoch 1300] ELBO: 4057; Loglik: -3260; Acc.: 0.455; Alpha RMSE: 0.103; Beta RMSE: 0.519
[Epoch 1400] ELBO: 4044; Loglik: -3139; Acc.: 0.476; Alpha RMSE: 0.114; Beta RMSE: 0.476
[Epoch 1500] ELBO: 3962; Loglik: -3199; Acc.: 0.468; Alpha RMSE: 0.130; Beta RMSE: 0.441
[Epoch 1600] ELBO: 3918; Loglik: -3159; Acc.: 0.465; Alpha RMSE: 0.126; Beta RMSE: 0.408
[Epoch 1700] ELBO: 4054; Loglik: -3138; Acc.: 0.482; Alpha RMSE: 0.147; Beta RMSE: 0.372
[Epoch 1800] ELBO: 3865; Loglik: -3170; Acc.: 0.490; Alpha RMSE: 0.122; Beta RMSE: 0.333
[Epoch 1900] ELBO: 3862; Loglik: -3143; Acc.: 0.481; Alpha RMSE: 0.141; Beta RMSE: 0.303
[Epoch 2000] ELBO: 4171; Loglik: -3091; Acc.: 0.486; Alpha RMSE: 0.131; Beta RMSE: 0.265
[Epoch 2100] ELBO: 3838; Loglik: -3123; Acc.: 0.479; Alpha RMSE: 0.155; Beta RMSE: 0.228
[Epoch 2200] ELBO: 3893; Loglik: -3137; Acc.: 0.481; Alpha RMSE: 0.151; Beta RMSE: 0.198
[Epoch 2300] ELBO: 3882; Loglik: -3142; Acc.: 0.478; Alpha RMSE: 0.155; Beta RMSE: 0.176
[Epoch 2400] ELBO: 3897; Loglik: -3106; Acc.: 0.480; Alpha RMSE: 0.137; Beta RMSE: 0.142
[Epoch 2500] ELBO: 3709; Loglik: -3069; Acc.: 0.494; Alpha RMSE: 0.150; Beta RMSE: 0.128
[Epoch 2600] ELBO: 3805; Loglik: -3069; Acc.: 0.497; Alpha RMSE: 0.143; Beta RMSE: 0.103
[Epoch 2700] ELBO: 3846; Loglik: -3077; Acc.: 0.506; Alpha RMSE: 0.127; Beta RMSE: 0.089
[Epoch 2800] ELBO: 3956; Loglik: -3094; Acc.: 0.496; Alpha RMSE: 0.122; Beta RMSE: 0.077
[Epoch 2900] ELBO: 3767; Loglik: -3112; Acc.: 0.492; Alpha RMSE: 0.159; Beta RMSE: 0.072
[Epoch 3000] ELBO: 3826; Loglik: -3135; Acc.: 0.481; Alpha RMSE: 0.148; Beta RMSE: 0.064
[Epoch 3100] ELBO: 3750; Loglik: -3063; Acc.: 0.500; Alpha RMSE: 0.156; Beta RMSE: 0.066
[Epoch 3200] ELBO: 3758; Loglik: -3103; Acc.: 0.489; Alpha RMSE: 0.154; Beta RMSE: 0.086
[Epoch 3300] ELBO: 3842; Loglik: -3111; Acc.: 0.496; Alpha RMSE: 0.155; Beta RMSE: 0.085
[Epoch 3400] ELBO: 3687; Loglik: -3046; Acc.: 0.502; Alpha RMSE: 0.140; Beta RMSE: 0.106
[Epoch 3500] ELBO: 3736; Loglik: -3123; Acc.: 0.483; Alpha RMSE: 0.137; Beta RMSE: 0.109
[Epoch 3600] ELBO: 3753; Loglik: -3104; Acc.: 0.489; Alpha RMSE: 0.146; Beta RMSE: 0.109
[Epoch 3700] ELBO: 3806; Loglik: -3092; Acc.: 0.484; Alpha RMSE: 0.143; Beta RMSE: 0.130
[Epoch 3800] ELBO: 3815; Loglik: -3157; Acc.: 0.470; Alpha RMSE: 0.139; Beta RMSE: 0.136
[Epoch 3900] ELBO: 3711; Loglik: -3085; Acc.: 0.497; Alpha RMSE: 0.153; Beta RMSE: 0.145
[Epoch 4000] ELBO: 3742; Loglik: -3140; Acc.: 0.484; Alpha RMSE: 0.131; Beta RMSE: 0.156
[Epoch 4100] ELBO: 3720; Loglik: -3102; Acc.: 0.493; Alpha RMSE: 0.147; Beta RMSE: 0.172
[Epoch 4200] ELBO: 3652; Loglik: -3052; Acc.: 0.499; Alpha RMSE: 0.137; Beta RMSE: 0.174
[Epoch 4300] ELBO: 3758; Loglik: -3139; Acc.: 0.477; Alpha RMSE: 0.138; Beta RMSE: 0.172
[Epoch 4400] ELBO: 3690; Loglik: -3077; Acc.: 0.492; Alpha RMSE: 0.143; Beta RMSE: 0.167
[Epoch 4500] ELBO: 3654; Loglik: -3079; Acc.: 0.497; Alpha RMSE: 0.145; Beta RMSE: 0.170
[Epoch 4600] ELBO: 3664; Loglik: -3073; Acc.: 0.495; Alpha RMSE: 0.145; Beta RMSE: 0.169
[Epoch 4700] ELBO: 3776; Loglik: -3135; Acc.: 0.491; Alpha RMSE: 0.152; Beta RMSE: 0.169
[Epoch 4800] ELBO: 3727; Loglik: -3142; Acc.: 0.494; Alpha RMSE: 0.140; Beta RMSE: 0.177
[Epoch 4900] ELBO: 3670; Loglik: -3147; Acc.: 0.479; Alpha RMSE: 0.148; Beta RMSE: 0.171
Elapsed time: 53.04185152053833
True alpha: [-0.8 0.8 1.2]
Est. alpha: [-0.8142185 0.577659 1.2801749]
BETA_XF1: -0.814
BETA_XF2: 0.578
BETA_XF3: 1.280
True zeta: [-0.8 0.8 1. -0.8 1.5]
Est. zeta: [-0.9568578 1.0457484 1.2734946 -0.8237798 1.5319899]
BETA_XR1: -0.957
BETA_XR2: 1.046
BETA_XR3: 1.273
BETA_XR4: -0.824
BETA_XR5: 1.532
CPU times: user 11min 11s, sys: 1.44 s, total: 11min 12s
Wall time: 56.4 s
The “results” dictionary containts a summary of the results of variational inference, including means of the posterior approximations for the different parameters in the model:
results
{'Estimation time': 53.04185152053833,
'Est. alpha': array([-0.8142185, 0.577659 , 1.2801749], dtype=float32),
'Est. zeta': array([-0.9568578, 1.0457484, 1.2734946, -0.8237798, 1.5319899],
dtype=float32),
'Est. beta_n': array([[-0.6056188 , 2.7274601 , 2.63112 , 1.2117751 , 2.559119 ],
[-0.18624985, 2.6991503 , 2.460729 , -0.46464953, 2.4061751 ],
[-0.71496165, 2.0986056 , 1.0234447 , 0.41272736, 2.93658 ],
...,
[-0.90784115, 0.4284096 , 1.5066543 , -1.4596953 , 2.0420322 ],
[-0.4305307 , 1.3227816 , 1.5597908 , -1.4394307 , 1.5375981 ],
[-1.0581803 , 1.0976315 , 0.9074108 , -1.1716478 , 2.017804 ]],
dtype=float32),
'ELBO': 3609.063232421875,
'Loglikelihood': -3087.33642578125,
'Accuracy': 0.49639999866485596}
This interface is currently being improved to include additional output information, but additional information can be obtained from the attributes of the “mxl” object for now.